1. 목표
- 데이터 프레임의 범주형 데이터 빈도수 구하기
2. 도구
- Google Colaboratory
3. 사전 정보 확인
[파이썬] 외부 데이터 (Gibhub) 불러오기와 정보 확인하기 (tistory.com)
[파이썬] 외부 데이터 (Gibhub) 불러오기와 정보 확인하기
1. 개요 및 목표 - 판다스 패키지에서 제공하는 read_csv 메소드를 이용해서 외부 데이터를 불러오기. - 불러온 외부 데이터 (데이터 프레임 형태) 의 컬럼 정보, 데이터타입, 결측치 정보, 기초 통계
iotcyuty.tistory.com

3. 문제 파악
- 위 기초통계량에 데이터를 확인하여 Sex, Pclass 에 대한 정보를 확인하고자 한다.

- 위 head(20) 을 통해 데이터프레임 형태를 확인한 결과 Pclass 는 1,2,3,... 의 범주형 데이터를 가지는 형태이고, Sex 는 male, female 데이터 범주를 가지는 형태임을 확인할 수 있다.
- 간략한 코딩을 통해 Pclass 의 빈도수와 Sex 의 빈도수를 확인해 보고자 한다.
4. 코드작성
import pandas as pd # 판다스 패키지 임포트
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv") # 타이타익 데이터 읽기 || 판다스 데이터프레임
## df.head(20) # 데이터 구조 파악하기
print("****Pclass 범주 데이터 빈도수 확인하기****") # 문구 출력
grp_Pclass = df.groupby("Pclass") # 그룹지정
print(grp_Pclass.size())
print(type(grp_Pclass))
print("\n\n") # 개행문자로 분리
print("****Sex 범주 데이터 빈도수 확인하기****") # 문구 출력
grp_sex = df.groupby("Sex") # 그룹지정
print(grp_sex.size())
print(type(grp_sex))
5. 결과출력

6. 해석
- groupby 메소드와, size 메소드를 이용하여 데이터프레임의 범주형 데이터를 그룹핑시킨 후 각 범주에 대한 빈도수 (개수)를 구해보았다.
- Pclass 는 3등급이 가장 많았고, Sex 는 male이 더 많이 탑승하고 있었다는 것을 확인했다.
- 그리고 데이터 프레임에 범주형 컬럼을 groupby 시킨 후 생성되는 데이터는 groupby.generic.DataFrameGroupBy 라는 데이터 타입 (class 객체) 로 생성됨을 알 수 있다.
pandas.DataFrame.groupby — pandas 2.0.1 documentation (pydata.org)
pandas.DataFrame.groupby — pandas 2.0.1 documentation
When calling apply and the by argument produces a like-indexed (i.e. a transform) result, add group keys to index to identify pieces. By default group keys are not included when the result’s index (and column) labels match the inputs, and are included ot
pandas.pydata.org
print("\n\n")
grp_sex2 = df.groupby('Sex').mean() # 그룹바이
print(grp_sex2)
print(type(grp_sex2))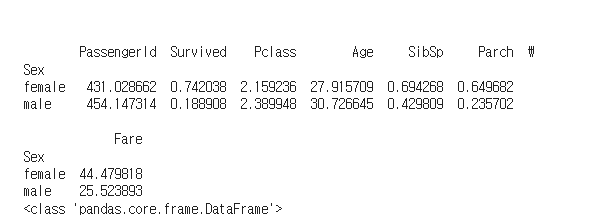
- 위와 같이 groupby('Sex').mean() 를 실행한 결과이다.
- Sex 라는 범주형 데이터를 그룹핑을 시키는 것까지는 동일하나 Size() 메소드를 실행한 결과와
mean() 메소드 처리 이후의 데이터 타입이 다른 것을 알 수 있다.
- mean() 메소드 처리 이후에 반환되는 값은 frame.DataFrame 데이터 타입이다.
pandas.DataFrame — pandas 2.0.1 documentation (pydata.org)
pandas.DataFrame — pandas 2.0.1 documentation
Dict can contain Series, arrays, constants, dataclass or list-like objects. If data is a dict, column order follows insertion-order. If a dict contains Series which have an index defined, it is aligned by its index. This alignment also occurs if data is a
pandas.pydata.org
'Python' 카테고리의 다른 글
| [Python] 표준정규분포(정규분포) 데이터 생성 (0) | 2023.05.09 |
|---|---|
| [Python] Seaborn 패키지 (0) | 2023.05.08 |
| [Python] Matplotlib.pyplot 상자수염 그래프 그리기 (0) | 2023.05.08 |
| [Python] Matplotlib.pyplot 히스토그램 그래프 그리기 (0) | 2023.05.08 |
| [파이썬] 외부 데이터 (Gibhub) 불러오기와 정보 확인하기 (0) | 2023.05.04 |