1. 개요 및 목표
- 판다스 패키지에서 제공하는 read_csv 메소드를 이용해서 외부 데이터를 불러오기.
- 불러온 외부 데이터 (데이터 프레임 형태) 의 컬럼 정보, 데이터타입, 결측치 정보, 기초 통계량 확인하기 예제 수행.
1-1. 사용 도구
- Google Colaboratory
2-1. 작성 코드
'''
[목표]
1. 판다스 패키지 임포트하기
2. 판다스 패키지 내에 read_csv 메소드 사용하기
3. 데이터 프레임 정보 확인하기기
'''
import pandas as pd # 판다스 패키지 임포트
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv") # 타이타익 데이터 읽기 || 판다스 데이터프레임
df.info() # 정보 확인
2-1-1. 코드 실행 결과
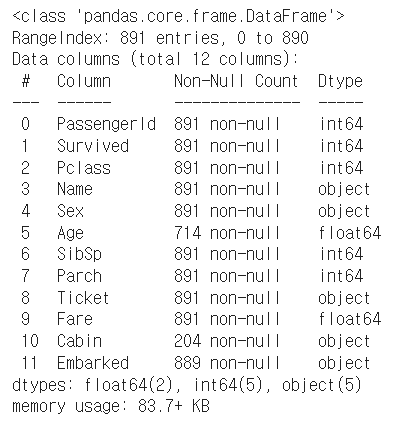
2-1-2. 해설
- 코드 실행결과로 CSV 파일을 데이터프레임 형태로 불러왔다.
- 각 열(Column) 에 대한 정보와 결측값 정보, 데이터 타입 정보를 확인할 수 있다.
2-2. 작성코드
import pandas as pd # 판다스 패키지 임포트
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv") # 타이타익 데이터 읽기 || 판다스 데이터프레임
df.head(20) # 20개 정보 확인하기
2-2-1. 실행결과

2-2-1. 해설
- 데이터 프레임의 20개 정도만 대략적인 내용이나 패턴을 파악하기 위한 메소드 head() 를 사용해 보았다.
2-3. 작성코드
import pandas as pd # 판다스 패키지 임포트
df = pd.read_csv("https://raw.githubusercontent.com/datasciencedojo/datasets/master/titanic.csv") # 타이타익 데이터 읽기 || 판다스 데이터프레임
df.describe(include='all') # 간단한 통계 정보 확인하기2-3-1. 실행결과

2-3-2. 해설
- describe(include='all') 을 통해 데이터 프레임의 간략한 통계 정보 (기초통계량)를 한눈에 파악할 수 있다.
- 결측치를 제외한 데이터의 갯수(count),
- 범주형 데이터의 개수 (unique),
- 범주형 데이터에서 가장 많이 출현한 데이터 값 (top),
- 범주형 데이터에서 가장 많이 출현한 데이터의 개수 (freq),
- 연속형 데이터의 산술평균 (mean)
- 연속형 데이터의 표준편차 (std)
- 연속형 데이터의 최소값 (min)
- 연속형 데이터의 1분위수 (25%)
- 연속형 데이터의 2분위수 (50%)
- 연속형 데이터의 3분위수 (75%)
- 연속형 데이터의 최대값 (max)
[통계] 상자 수염 그림 as 박스 플롯 (Box Plot) (tistory.com)
[통계] 상자 수염 그림 as 박스 플롯 (Box Plot)
Box Plot 을 통해 알 수 있는 것 a. 이상치 존재 여부 b. 데이터 분포의 최소값, 제1분위 (Q1), 중앙값, 제3분위 (Q3), 최대값 사분위범위는 제3분위에서 제1분위를 뺀값 (Q3-Q1) 이다.
iotcyuty.tistory.com
'Python' 카테고리의 다른 글
| [Python] 표준정규분포(정규분포) 데이터 생성 (0) | 2023.05.09 |
|---|---|
| [Python] Seaborn 패키지 (0) | 2023.05.08 |
| [Python] Matplotlib.pyplot 상자수염 그래프 그리기 (0) | 2023.05.08 |
| [Python] Matplotlib.pyplot 히스토그램 그래프 그리기 (0) | 2023.05.08 |
| [파이썬] 데이터프레임 - 범주형 데이터 빈도수 구하기 (0) | 2023.05.04 |