[Python] Seaborn 패키지
1. 목표
- Seaborn python package
2. 도구
- Google Colaboratory
3. 설명
import seaborn as sns
help(sns)

GitHub - mwaskom/seaborn-data: Data repository for seaborn examples
GitHub - mwaskom/seaborn-data: Data repository for seaborn examples
Data repository for seaborn examples. Contribute to mwaskom/seaborn-data development by creating an account on GitHub.
github.com
import seaborn as sns
titanic = sns.load_dataset("titanic") # 타이타닉 데이터 불러옴
print(type(titanic)) # 데이터타입 확인
titanic.head(20) # 데이터 정보 일부 확인
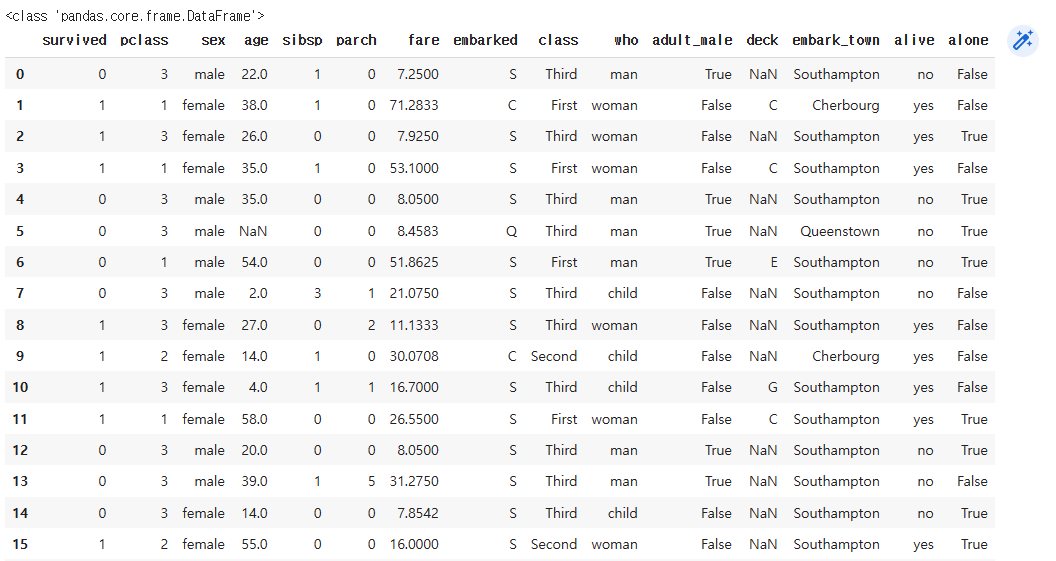

- 데이터를 살펴보니 기존에 포스팅하였던 타이타닉 데이터와는 컬럼이름과 약간의 데이터 타입이 조금 다른걸 알 수 있다.
- 어쨌든 데이터 프레임 형태로 넘어오니 데이터의 이름과 타입을 잘 살펴서 코드를 작성해 보면 금방 적응할 수 있을 것 같다.
import seaborn as sns
help(sns.load_dataset)
GitHub - mwaskom/seaborn-data: Data repository for seaborn examples
GitHub - mwaskom/seaborn-data: Data repository for seaborn examples
Data repository for seaborn examples. Contribute to mwaskom/seaborn-data development by creating an account on GitHub.
github.com
- 링크를 확인해보니 빅데이터 연습을 위해 많이 사용하는 titatic뿐만 아니라 Iris 등 여러가지 데이터 셋을 가지고 있으니 빅데이터 연습할 때 충분히 사용해 볼만 할 듯 하다.